![【第8回】 スタートが揃うとインが強いのか [ボートレース×統計学]](https://funaneko.com/images/articles/brstats008/eye_chatcher.webp)
【第8回】 スタートが揃うとインが強いのか [ボートレース×統計学]
スマホやパソコンで検索すれば、多くのことが解決できる便利な時代になりました。
ボートレースについても例外ではなく、あらゆる情報が簡単に見ることができますよね。
ただ、ネットで見つかる情報の中に私自身が本当に知りたかったものはありませんでした。
そうなんです。どれだけネットを探しても、ボートレースの完全な攻略法は見つからないのです。
だからこそ、散らばった情報の断片を組み合わせて独自の予想法を作るしか、私たちにはないのです──

ボートレースの「常識」をデータで確かめる!
前回までの「ボートレース×統計学」では、的中率向上のために今後活用する仮説検定の方法や、その用語について解説してきました。
まだお読みでない方は下にまとめていますので、目を通していただければ今回の記事もより分かりやすいかと思います。

今回から実際に統計学を駆使して、ボートレースのあらゆる事柄を検証していきます。
その初回のテーマは、SNSで見かけたフォロワーさんの投稿をヒントに、このような内容を考えました。

ボートレースは、公営競技の中でもスタート方法が独特であることは周知の通りでしょう。
また、ボートレースは極端にインコースが強いことは紛れもない真実です。
そこで、皆さんも一度は聞いたことがあるかもしれない「ボートレースはスタートが揃うとインコースが強い」──この通説を統計学で検証します。
一気にお見せするので、いつもよりもボリュームのある記事になっていますが、ぜひ最後までお付き合いください。

スタートの「揃い具合」を数値化する
統計学がどのように結論に導くのか、順を追ってお話します。
統計学で解明する前に、まずは知りたい情報を整理するところから始まります。
まず、今回のテーマの場合「スタートが揃う」とはどういう状況なのかを明確にする必要があります。
ボートレースの公式サイトでは、出走レーサーのスタートタイミングやスリットの様子を分かりやすい図解で確認できますよね。
しかし、実際に数字を用いて「揃ったスタート」を定義するには、具体的な数値が必要です。
そこで、SNSでアンケートを実施しました。こういうとき、ネットは本当に便利ですね。
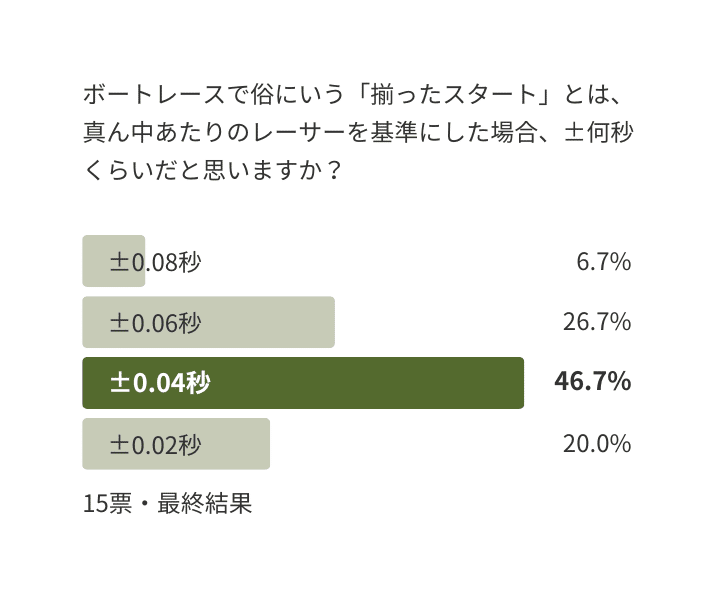
アンケートの結果、スタート時点で中心付近のレーサーから±0.04秒を揃ったスタートと考える人が多かったため、ここではその値を基準とします。
つまり、スタートタイミングの最速と最遅の差が0.08秒以内なら、ここでは「揃ったスタート」と定義します。
いよいよ検証開始! まずはデータ収集から
それでは整理した情報をもとにして、データ分析を始めましょう。
今回は、ある半年間で行われたレースのうち、欠場レーサーなどがなく6艇でスタートし、フライングや出遅れがなかった27049レースを対象に「スタートが揃うとインコースが強いのか」を検証していきます。
まず、「インコースは本当に強いのか?」を調べるために、27049レースの1コースの勝率を算出しました。その値は55.5%でした。
次に、その中から先ほど定義した「揃ったスタート」のレースを詳しく調べます。
すると、スタートタイミングの最速と最遅の差が0.08秒以内だったレースは8178レースあり、その1コースの勝率は63.4%とわかりました。

では、実際にこれらのデータをもとに「55.5%と63.4%の間に統計的な違いはあるのか」を統計学を使って検証してみましょう。
「63.4%の事象を繰り返すことで、55.5%に収束しなさそうか?」と表現したほうが伝わりやすいかもしれませんね。
判断がぶれないために決めておくこと

上の図に従って仮説検定を進めます。まずは青色の「手法を選ぶ」から始めましょう。
今回、私たちは「全体の1コースの勝率と、スタートが揃ったときの1コースの勝率を比べたとき違いがあるのか」を調べようとしています。
それを検証するための手法を、最初に明確にしておきます。
ある事柄の割合(比率)と全体の割合を比べる際には、仮説検定の手法のひとつ、母比率の検定を使います。
さらに「違いがあるのか」を知りたいので、全体の割合との違いを調べるために、そのうちの両側検定を用いて検証します。
つまり、この検証で使う仮説検定の手法は「母比率の検定(両側検定)」であると、ここで決めておきます。

「たまたま」の可能性を数値で考える

次に、緑色の「有意水準の設定」です。
有意水準とは、「偶然と必然の境界線の基準を数値で示したもの」と過去の記事で解説しています。
本来、この値は検証の手法や内容に応じて自由に設定できるものですが、一般的によく使われる5%という数値を私たちも採用することにします。
これは、「5%未満の確率で起こることを『稀な事象』とする」という、検証するためのルールを設定する作業になります。
「55.5%と63.4%というふたつの割合の違いは、5%という稀に起こる違いなのか、はたまた珍しくない範囲なのか?」といったニュアンスになります。
検証の土台! ふたつの仮説を設定しよう

次に、黄色の「仮説を立てる」です。
仮説検定は、「帰無仮説をもとに検証し、それを棄却できれば対立仮説を主張する」というように展開していきます。
そのため、あらかじめ、これらの仮説を設定しておく必要があります。
一般的には「知りたいことを対立仮説に、その逆のことを帰無仮説に設定する」とされていますが、その理由も過去の記事で触れています。
今回、対立仮説には、私たちがそうであると期待する「スタートが揃ったときの1コースの勝率は、全レースの1コースの勝率と違いがあるといえる」としましょう。
そうなると、帰無仮説はその対となる「スタートが揃ったときの1コースの勝率は、全レースの1コースの勝率と違いがあるとはいえない」となります。
この帰無仮説をもとに、仮説検定を進めていきます。
白か黒か? 統計学で明確にする!
これで、仮説検定を行う準備が整いました。
ここで母比率の検定がどのようにして帰無仮説が妥当か、そうでないかを判断するかをご紹介しましょう。
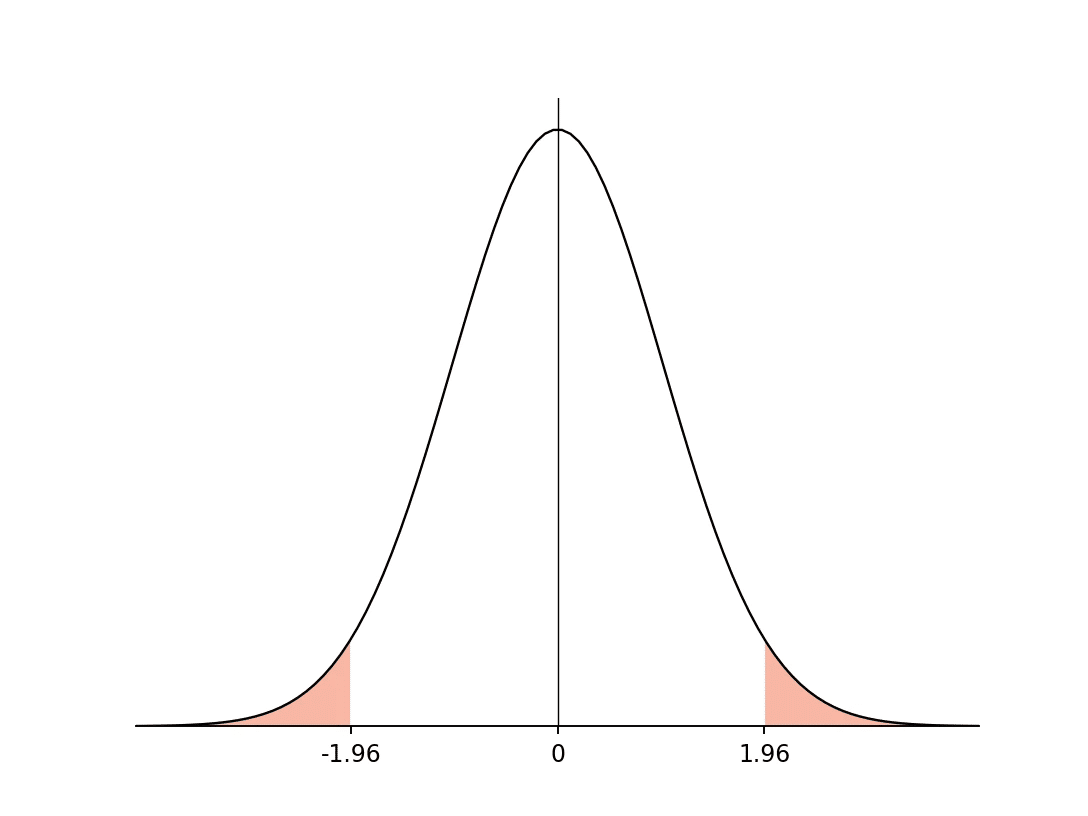
上のグラフは、母比率の検定で最終判断のときに使用するグラフです。
このあと算出する検定統計量をグラフの横軸に置き、その位置が白色の部分にあれば帰無仮説を棄却できない、それ以外にあれば帰無仮説を棄却し、対立仮説を採用します。
グラフの色分けは、統計手法や有意水準から算出される棄却限界値によるもので、白以外の部分(ピンクの部分)が帰無仮説を棄却するエリア、つまり棄却域です。
つまり、検定統計量が棄却域に入っていれば、帰無仮説を否定し、対立仮説を採用できます。これにより、私たちの仮説が統計的に裏付けられたことになります。

計算はこれだけ!必要な値を求める

それでは、仮説検定の流れのオレンジ色の項目、「検定統計量を計算する」に進みます。
先に、検証することに対して調べた数(8178レース)と確率(64.3%)、そして基準となる確率(55.5%)を使って、「検証するための値」となる検定統計量を算出します。

上の式に数値を代入して計算すると、検定統計量は14.38となりました。
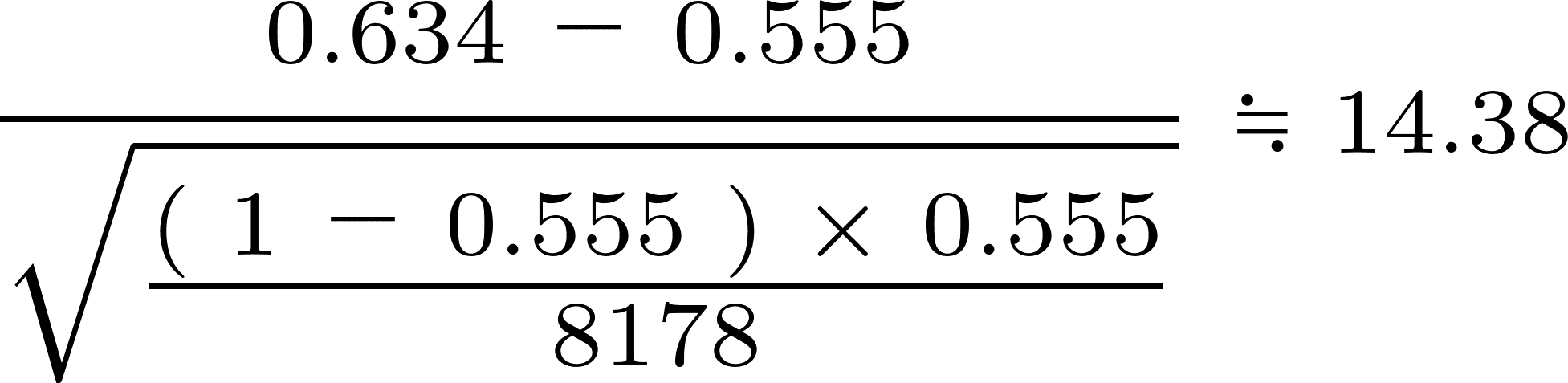
この値を実際にグラフの横軸に置き、帰無仮説を棄却できるかどうかを判断してみましょう。最後の赤色の項目になります。

統計の力で、通説の真偽を判定!
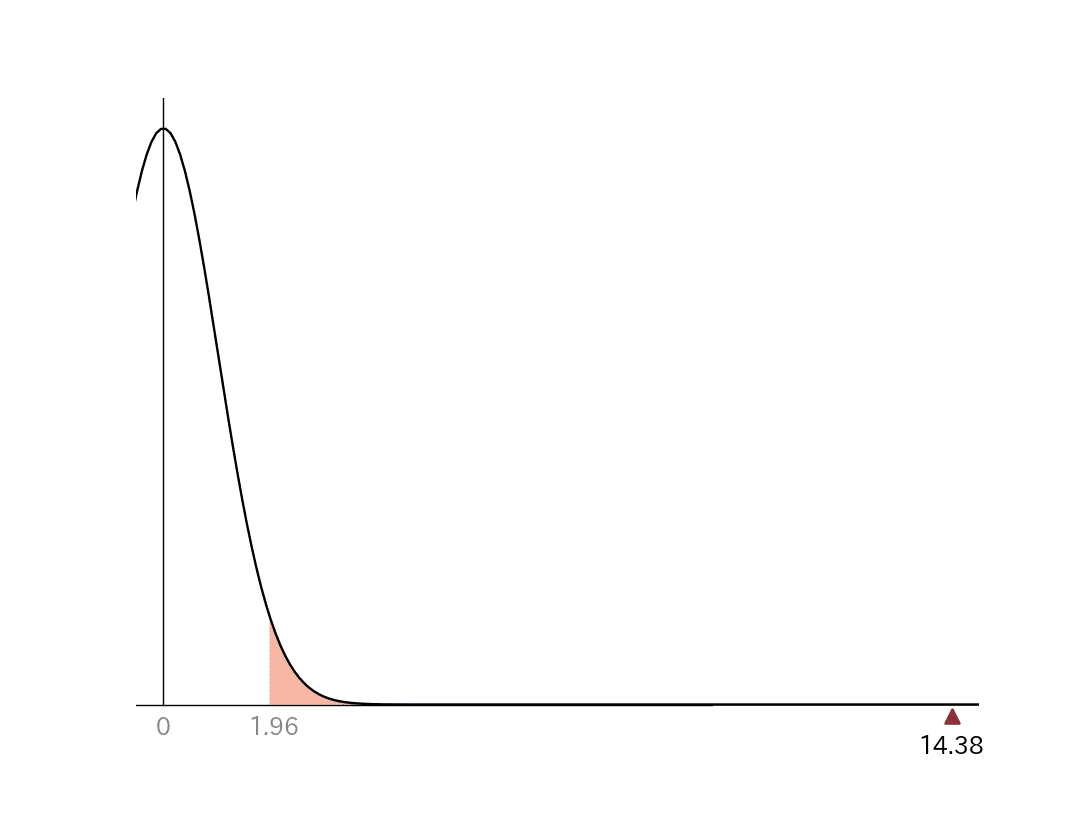
検定統計量の14.38という値は、グラフの白色の部分にはありません。これは統計学が「帰無仮説を棄却した」ということになります。
つまり対立仮説を採用し、スタートが揃ったときの1コースの勝率は、全体の1コースの勝率と違いがあるといえると主張することができます。
さらに、この値がプラス側の棄却域に入るため、スタートが揃ったときの1コースは強いと統計的にいえる結果となるのです。
ボートレースファンの間で知られる通説は、統計学的にも正しいこと分かりました──
このように仮説検定は進められるのです。
この結果を活かし、さらなる戦略を練る!
今回は駆け足になりましたが、母比率の検定を使って「スタートが揃ったときの1コースは強いのか」について検証しました。
この手法を使えば、全体の確率と知りたい事柄の確率の違いを、統計的に裏付けられた方法で判断できます。
今回のような「帰無仮説を棄却して、対立仮説を採用する」ような事柄をたくさん見つけ出し、独自の予想法を磨いていきましょう。
次回は、このデータをもとに、さらなる発見を探ります。
最後まで読んでいただき、ありがとうございました。